




The next parts of my MERN journey won't be specifically about the current chapter Node.js, because I'll revisit a lot of concepts that are equally applicable to JavaScript running in a browser. Just to throw a few keywords - I'm going to take a deep dive into
- the call stack
- execution context
- asynchronous JavaScript
- JavaScript runtime and JavaScript engine
- Web APIs
- the event loop
✏ The Call Stack
The call stack is a data structure that keeps track of which part of the code is currently running. When a script starts, the interpreter goes through the code, waiting to find a function invocation. Once it finds one, it creates an empty stack frame. If you've ever inspected the stack trace and wondered what's the anonymous function that's always on the bottom of the stack - here's your answer.
Every function call in the code essentially is equal to the creation of a stack frame, which contains the function, its parameters and all variables within its scope. It's a snapshot of the function's universe in that moment, located at a certain place in memory. You can also call it "execution context" instead of "snapshot". Once the function has executed and returned (or implicitly returned undefined after it has reached the end of its code block), the frame is popped off the stack, and the memory is cleared.
(I initially wanted to add an "unless..." to the above sentence to account for closures, but had a bright moment(?) and understood that clearing the memory after a function execution isn't the same as garbage collection. In the case of a closure, the snapshot of the inner function's universe is still intact, and untouched by the deletion of the outer function's snapshot. Additionally, the idea of "snapshots" of a function's universe in the moment that the function is invoked should help me in getting a deeper understanding of the this keyword, but now I really digress.)
Let's dive into some code instead.
✏ Synchronous code
I'll start with a very simple series of console.log statements, one of which is wrapped in another function. I'll do this in the browser, not in node, but I don't think it makes a difference for this point:
console.log(1);
log2();
console.log('end of script');
function log2(){
console.log(2)
}
The function calls are executed in order and unsurprisingly, the console prints:
1
2
'end of script'
What happens if I modify my log2 function so it performs an expensive operation? To simulate this, I'll include a while loop and let it count up to 1 billion. On my machine, that takes about 2 seconds to complete.
console.log(1);
log2_loop();
console.log('end of script');
function log2_loop(){
let i=0;
while(i < 1E9) {i++};
console.log(2)
}
Checking the output:
1
/* ... nothing happens for 2 seconds... */
2
'end of script'
The order of the console prints is still the same, but you can clearly see the delay if you try it yourself. This is an example how to block JavaScript's single thread. Nothing can execute until log2_loop has completed, and if this was running in a browser, the page would be completely unresponsive during that time.
Now I'll rewrite the function so that on first sight, it seems to do the same as before, except it doesn't - and that difference took me ages to figure out. I'll replace the while loop with a call to setTimeout:
function log2_timeout(){
setTimeout(() => console.log(2), 2000)
}
Here, my log2_timeout function still makes sure that the output is delayed by 2 seconds, just like the while loop did, but now the console prints:
1
'end of script'
/* ... nothing happens for 2 seconds... */
2
How can that happen? What's the difference between a delay caused by a while loop and a delay caused by setTimeout?
(Spoiler: it's because the loop is a synchronous operation handled by the JavaScript engine, setTimeout is an asynchronous operation handled by the runtime/environment)
✏ Inspecting the call stack
A simple way to inspect the call stack at a certain point in your code is to use console.trace(). A visualisation of the call stack using the log2_loop function would look like this:

Now the same, but with the log2_timeout function instead:
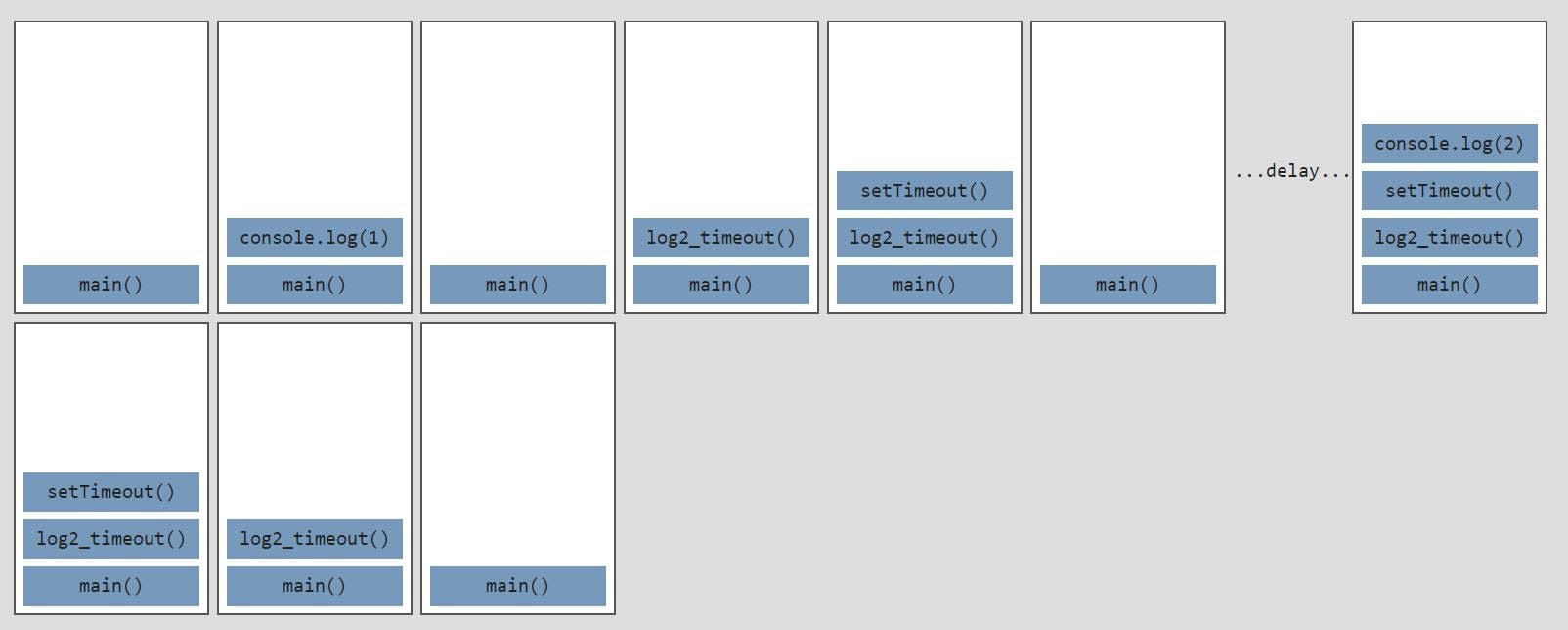
There's something very weird going on. After the call to setTimeout, the call stack is emptied, but after a 2 second delay, all those functions suddenly get pushed onto the stack again. Where are these coming from?
✏ JavaScript engine and JavaScript runtime
When it's said that "JavaScript is single-threaded", it actually means that "the JavaScript engine is single-threaded". However, the JavaScript runtime (which can be a browser or Node.js) can handle multiple threads at a time.
But before I dive deeper into that, I'd like to take a step back and just point out some observations that everyone who uses a computer is already familiar with. Computers usually have operating systems and applications, all controlled by user interaction. A user can open an application like a code editor, type some stuff into it with a keyboard, save it, close it, etc. Sometimes, the system is performing a CPU expensive operation, and becomes unresponsive for a while. I keep typing, but nothing appears on the screen. Then the application catches up, and all the text I entered suddenly appears. This means that even though nobody seemed to be at home when I knocked on the door with my keyboard, my input didn't go completely unnoticed. Someone saved it somewhere. They also saved my input in order. The letters appear exactly in the order that I typed them in, they're not scrambled up. Interacting with pages on the internet is very similar to this.
JavaScript was invented to add interactivity to websites. Users can click on buttons to start a download, elements can be inserted or removed from the DOM, or data can be fetched from a server with an AJAX request. Some of these operations require some time to complete, during which the website would be unresponsive, if those operations were all handled in the single thread of the JavaScript engine.
That's where the browser's Web APIs come to the rescue (or in the case of Node.js, those are C++ APIs). Any operation that should run asynchronously will be kept in the API's thread pool, some examples I've already mentioned are AJAX requests, setTimeout or DOM event listeners. What all these have in common is that they take a callback function.
Once the time consuming task is completed, the callback will be placed into a task queue or callback queue, but meanwhile, the JavaScript engine can just move on and execute the rest of the script, until its call stack is empty.
✏ The Event Loop
The connection between callback queue and call stack is the event loop. It's a continously running process that watches both. If there's a callback function in the queue waiting for execution, the event loop will first check the call stack. As soon as it's empty, it'll push the callback onto it.
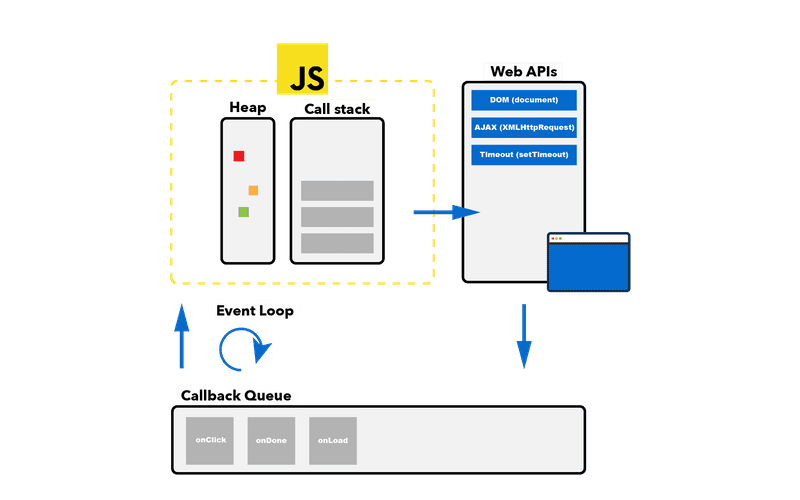 (
(✏ Recap
I've learned
- the call stack is a data structure to keep track of the code that's currently running
- every function call creates a new stack frame that gets pushed on top of the stack
- a stack frame is a snapshot of the function along with its parameters and variables, taken in the moment that the function is invoked
- once the function is done with its code, it gets popped off the stack
- asynchronous operations like
setTimeoutorfetcharen't part of the JavaScript engine, but are APIs provided and handled by the environment - the JavaScript engine has a single thread (a single call stack), the environment can handle multiple threads
- once the asynchronous operation is done, the callback function will be placed into the task queue or callback queue
- the call stack works according to LIFO (last in, first out)
- the callback queue works according to FIFO (first in, first out)
- the event loop is a friendly hamster that continuously checks if there's a function in the callback queue, waiting to be pushed back onto the call stack
✏ Resources
Any article about the call stack and event loop wouldn't be complete without a link to this excellent talk: What the heck is the event loop anyway
Collection of articles that I found really helpful:
Awesome-JavaScript-Interviews - Call Stack
JavaScript Event Loop And Call Stack Explained
A Visual Explanation of JavaScript Event Loop
JavaScript Asynchronous Programming and Callbacks
✏ Next:
- back to Node.js for a moment:
process.nextTick()andsetImmediate()
✏ Thanks for reading!
I do my best to thoroughly research the things I learn, but if you find any errors or have additions, please leave a comment below, or @ me on Twitter. If you liked this post, I invite you to subsribe to my newsletter. Until next time 👋
✏ Previous Posts
- Day 1: Introduction, Node.js, Node.js in the terminal
- Day 2:
npm, node_modules,package.jsonandpackage-lock.json, local vs global installation of packages - Day 3: Create a React app without create-react-app, Webpack, Babel
- Day 4:
npxand cowsay - Day 5:
npmvs.npx,npm audit, semantic versioning and update rules