




✏ MongoDB Aggregation: $group stage
With $group, you can completely restructure the collection, depending on different criteria of your choice. This stage makes the most sense when using it together with accumulators (see below), but I'll start with a few simple examples.
The syntax for the most basic group aggregation is:
<Model>.aggregate([
{ $group: { _id: <expression> } }
])
Here, the_id field is mandatory. It does not refer to the ObjectId that every record has by default. $group produces a new set of documents, and the id field depends on the expression (= field reference) that you grouped the collection by.
Let's look at the collection again:
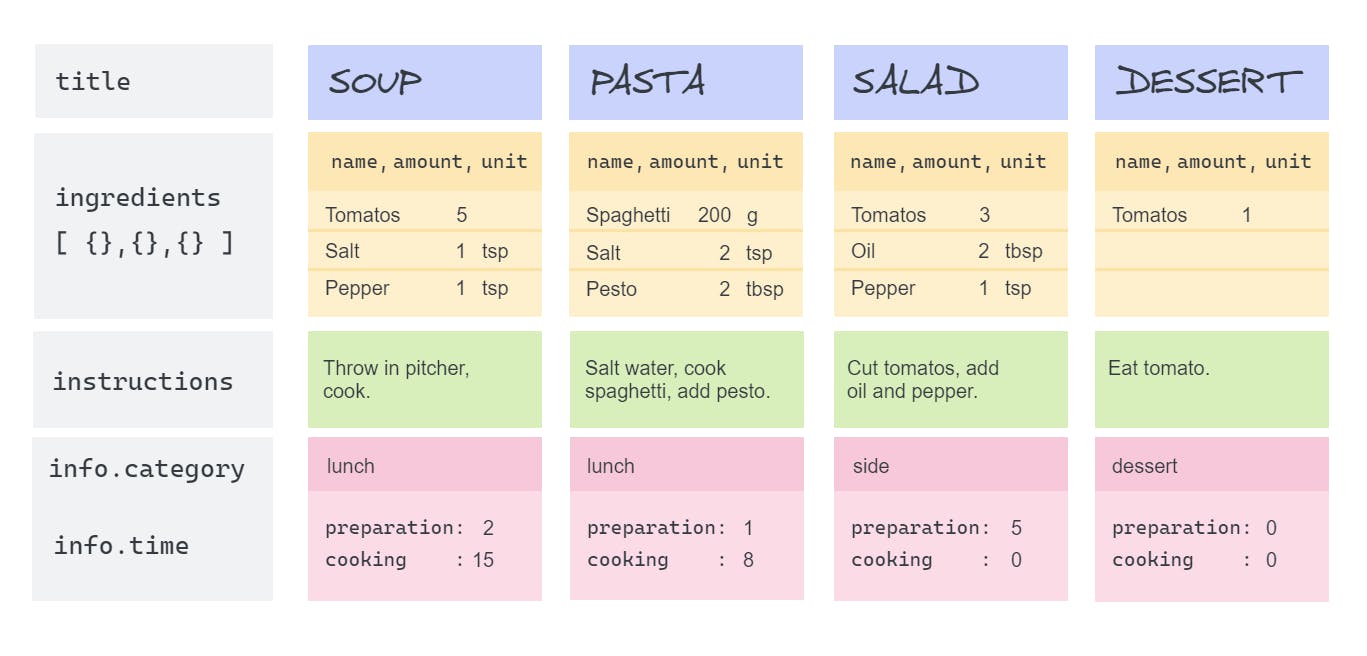
Grouping by Title
To get a list of all recipe titles, group by the title field. A field reference is indicated by wrapping the field name in quotes and a $:
Recipe.aggregate([
{ $group: { _id: '$title' } }
])
The output for this is a collection of documents that have only one property _id with the recipe title:
[
{ _id: 'Pasta' },
{ _id: 'Soup' },
{ _id: 'Dessert' },
{ _id: 'Salad' }
]
This is essentially the same as using .find({}) together with .select() to exclude the ingredients list and other fields. The difference is that $group returns only distinct documents, see the next example:
Grouping by Category
I have four recipes in three categories, grouping them by category:
Recipe.aggregate([
{ $group: { _id: '$info.category' } }
])
The output is a list of all different categories:
[
{ _id: 'lunch' },
{ _id: 'side' },
{ _id: 'dessert' }
]
Grouping by Info
The info field is a subdocument with two properties, the category and another object with preparation and cooking time. Grouping by '$info' results in four documents with only the info subdocument:
Recipe.aggregate([
{ $group: { _id: '$info' } }
])
// result
[
{ _id: { category: 'side', time: [Object] } },
{ _id: { category: 'dessert', time: [Object] } },
{ _id: { category: 'lunch', time: [Object] } },
{ _id: { category: 'lunch', time: [Object] } }
]
Mongo does a deep comparison of objects (and arrays). If I had two or more recipes in the same category and with the same values for info.time.preparation and info.time.cooking, they would not be considered distinct.
Grouping by Ingredients
Likewise, grouping by ingredients results in four documents with only their ingredients arrays (I'll talk about arrays in more detail when describing the $unwind stage). Grouping by '$ingredients.name' would return a list of ingredients for each document:
[
{ _id: [ 'tomatos', 'salt', 'pepper' ] },
{ _id: [ 'spaghetti', 'salt', 'pesto' ] },
{ _id: [ 'tomatos', 'oil', 'pepper' ] },
{ _id: [ 'tomatos' ] }
]
This list alone isn't very helpful though, since the title of the recipe is missing in the output.
✏ Adding more fields to the result collection
Instead of only one <expression>, pass an object with all fields that should be included. You can rename the keys of the resulting document:
Recipe.aggregate([
{ $group: { _id: {
recipeName: '$title',
ingredientsList: '$ingredients.name' }
} }
])
// result
[
{ _id: { recipeName: 'Soup', ingredientsList: [Array] } },
{ _id: { recipeName: 'Dessert', ingredientsList: [Array] } },
{ _id: { recipeName: 'Salad', ingredientsList: [Array] } },
{ _id: { recipeName: 'Pasta', ingredientsList: [Array] } }
]
Adding more fields generally increases the number of result documents. If I had a collection with recipes in 5 categories and another field for "warm/cold", then grouping by the latter will result in 2 documents. Assuming that all categories have both warm and cold dishes, grouping by both "warm/cold" and category will result in 10 documents, because there's 10 distinct combinations.
But again, a result that only lists those combinations makes no sense in this case. I already know them, because I'm the one who decided which categories the recipes in my collection can have. It would only make sense if you have a database that's edited by many different users who are free to choose and name a category themselves.
The real power of $group lies in adding accumulators. Those allow for example to find out how many recipes I have in each category.
✏ Accumulators
The most common accumulators in the $group stage are $sum, $min, $max or $avg. The syntax is:
<Model>.aggregate([
{ $group: {
_id: <expression>,
<field>: { <accumulator>: <expression> }
}
}
])
To find out how many recipes I have in each category, I'd use the $sum operator with an expression (value) of 1:
Recipe.aggregate([
{ $group: {
_id: '$info.category',
total: { $sum: 1 }
}
}
])
// result
[
{ _id: 'lunch', total: 2 },
{ _id: 'dessert', total: 1 },
{ _id: 'side', total: 1 }
]
Here, $sum is used as a counter (indicated by the value of 1).
Pitfalls
Note that it makes a big difference how you group and count. In the first example below, I'm counting documents in each category (same as above), the second example gets a list of distinct categories and pointlessly returns the information that each distinct document is present with a total count of 1:
// counting documents in each category:
{ $group: { _id: '$info.category', total: { $sum: 1 } } }
// result
[
{ _id: 'lunch', total: 2 },
{ _id: 'dessert', total: 1 },
{ _id: 'side', total: 1 }
]
// pointless:
{ $group: { _id: { category: '$info.category', total: { $sum: 1 } } } }
// result
[
{ _id: 'lunch', total: 1 },
{ _id: 'dessert', total: 1 },
{ _id: 'side', total: 1 }
]
Accumulators with a field reference
Instead of using an accumulator like $sum with a value of 1, it can also be used with a field reference, to calculate the total preparation time per category. It's a slightly nonsensical query though, so I'll take $avg instead, to get the average preparation time per category:
Recipe.aggregate([
{ $group: {
_id: '$info.category',
averagePrepTime: { $avg: '$info.time.preparation' }
}
}
])
// result
[
{ _id: 'lunch', averagePrepTime: 1.5 },
{ _id: 'dessert', averagePrepTime: 0 },
{ _id: 'side', averagePrepTime: 10 }
]
✏ Grouping by null
Grouping by null allows to count/accumulate values for the whole collection. It returns one document (because there's only one distinct null value). If I take the above example and group by null instead of $info.category:
Recipe.aggregate([
{ $group: {
_id: null,
averagePrepTime: { $avg: '$info.time.preparation' }
}
}
])
// result
[ { _id: null, averagePrepTime: 3.25 } ]
With such a small collection of 4 recipes, it's difficult to use accumulators in any meaningful way, so I'll add some examples with a more realistic collection, with combinations of $match and $group:
✏ User collection: $match and $group
Imagine you have a collection of users, following this Model:
{
email: String,
name: String,
age: Number,
location: {
address: String,
country: String
}
isOnline: Boolean
}
Grouping by '$age' would return a list of all distinct age values in the collection. Adding accumulators, you can extract information about each group.
To find out how many are online, grouped by age, you'd first use $match to find all documents where isOnline is true, then use $group with a $sum accumulator. The result is an (unsorted) list of objects with age/online properties:
User.aggregate([
{ $match: { isOnline: true } },
{ $group: { _id: '$age', online: { $sum: 1 } } }
])
// result
[
{ _id: 18, online: 143 },
{ _id: 45, online: 98 },
{ _id: 26, online: 122 },
...
]
One last example: To find out the average age of users, grouped by country:
User.aggregate([
{ $group: {
_id: '$location.country',
averageAge: { $avg: '$age' }
}
}
])
// result
[
{ _id: 'USA', averageAge: 25.34 },
{ _id: 'India', averageAge: 22.78 },
{ _id: 'Brazil', averageAge: 23.62 },
...
]
That's it for the $group stage. Next post: $project stage.
✏ Resources
I highly recommend this YouTube playlist:
✏ Recap
This post covered:
- MongoDB aggregation:
$groupstage
✏ Thanks for reading!
I do my best to thoroughly research the things I learn, but if you find any errors or have additions, please leave a comment below, or @ me on Twitter. If you liked this post, I invite you to subscribe to my newsletter. Until next time 👋
✏ Previous Posts
You can find an overview of all previous posts with tags and tag search here: