




✏ Change of Plan
Yes, again. I've mentioned that I have difficulties staying focussed.
It was great to get my hands on the keyboard again and code a short Hangman App, but the truth is - I haven't really learned much about communicating with a server, I've learned nothing about MongoDB or Express.js, I only solidified my React skills. Same would happen if I continued with my React Quiz App. Getting the data for the questions and answers is one short request using fetch() (which I've already accomplished with my Hangman), and the rest would be pure Frontend.
✏ What's next then?
A fellow developer recommended this Fullstack course from Open University. I've gone through parts 0 (what's happening in detail in a network request) and half of part 1 (building the front end of a couple of projects) today, and I'm quite impressed with how much I've learned already. I'll continue to go through the whole course and write my summaries here. That seems to be a more efficient approach than randomly stumbling through what I think would be relevant.
Diving right in with the first chapter:
✏ Details of Network Requests
Whenever you open a browser and type in an address to visit a web page, there's already so much going on. I've mostly ignored the Network tab in my Chrome's developer tools until now, but checking that out gives tons of information.
Just opening a webpage usually leads to a number of things going back and forth between client and server. There is a tab "Waterfall" that indicates what was loaded when, and how long it took.
Request and Response Headers
The client request includes a Request Header, containing information about
- the request method (GET in this case)
- the path to the desired file
- and tons of other stuff that I'll put aside for now
If the server response has status code 200, it means that the request was successful. The Response Header that's coming back with the requested information includes the content type (otherwise the browser wouldn't know how to process the file). The most common content types are
- text/html
- text/css
- image/png, image/jpg etc
- application/javascript
- application/json
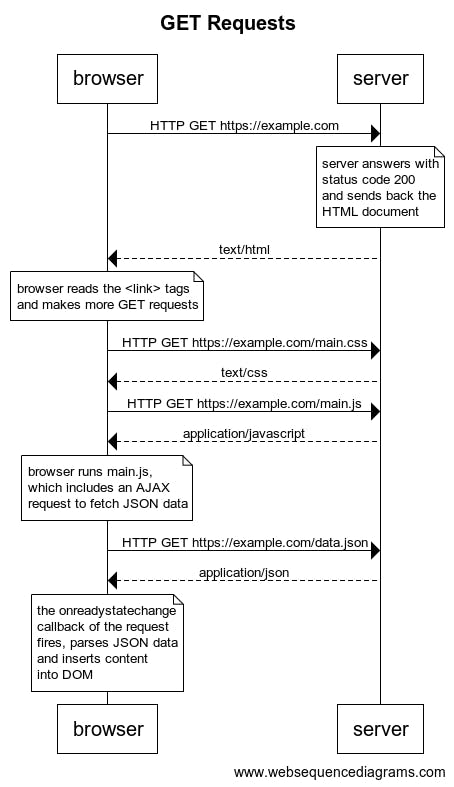
GET Requests
Most of the time, a webpage isn't just a HTML document. It has a number of <link> tags in its head, pointing at more files, so those are loaded next. The browser reads the tags and makes a new GET request for each to get the files. It might also receive a script, containing code to download more data.
A diagram to illustrate a typical case would be this:
(made with websequencediagrams.com/)
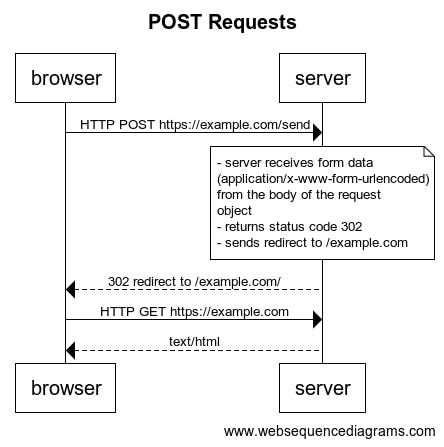
POST Requests (oldschool)
Whenever a form is submitted to a server, the browser makes a POST request to the address that it finds in the action attribute of the form. The request header therefore includes POST as method, and a path leading to where the data should be processed.
If the request was successful:
- the server processes the data (often, writes it in a database)
- server responds with status code 302 Found
- response header includes new location (redirects browser back)
From there, the whole cascade of follow-up requests starts again (although I suspect that this is oversimplified and doesn't account for possible caching).
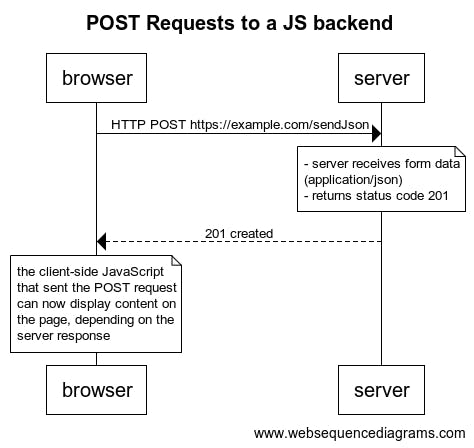
POST Requests (from SPA)
For a single page app (SPA) with a JavaScript backend, this process looks a bit different. Submitting the form is handled by the client-side JavaScript (in my example above, that was <main.js>):
- it prevents the default page reload
- instead of content-type application/x-www-form-urlencoded, it sends a JSON object (application/json) to the server
- server responds with 201 Created
There will be no more requests from the browser from here. Whatever the page should show in the case of a successful (or unsuccessful) form submit depends on the logic in <main.js>, which is already in the client's browser.
✏ Resources
Fundamentals of Web Apps from Open University
✏ Recap
I've learned
- what really goes on in a GET request
- how to follow the cascade of requests in the dev tools' Network tab
- what's in a Request Header/Response Header
- difference between a traditional POST request (presumably processed with PHP) and a POST request to a JavaScript backend
✏ Next:
- following the FullStackOpen course
✏ Thanks for reading!
I do my best to thoroughly research the things I learn, but if you find any errors or have additions, please leave a comment below, or @ me on Twitter. If you liked this post, I invite you to subsribe to my newsletter. Until next time 👋
✏ Previous Posts
- Day 1: Introduction, Node.js, Node.js in the terminal
- Day 2:
npm, node_modules,package.jsonandpackage-lock.json, local vs global installation of packages - Day 3: Create a React app without create-react-app, Webpack, Babel
- Day 4:
npxand cowsay - Day 5:
npmvs.npx,npm audit, semantic versioning and update rules - Day 6: Call stack, event loop, JavaScript engine, JavaScript runtime
- Day 7: Call stack and event loop in Node.js,
setImmediate() - Day 8:
setImmediate(),process.nextTick(), event loop phases in Node.js - Day 9: Network requests with
XMLHttpRequestand callbacks - Day 10: Promises
- Day 11: Network requests with
XMLHttpRequestand Promises - Day 12: React Quiz App part 1
- Day 13: React Hangman